The use of auxiliary qubits in MCX
I will look at auxiliary qubits, how these can be used in MCX gates, and their effect on the overall depth of a quantum circuit when transpiled to a specific QPU.

In this time of NISQ quantum computing, we want circuits to be as shallow as possible. This will ensure the least amount of errors will creep in because of non-perfect qubits. But also, in the fault-tolerant domain, you want circuits to be as efficient as possible to minimize run time.
One way of making quantum circuits more shallow is to use auxiliary qubits where possible. This is a trade-off, you will use more qubits, but the total depth of the circuit can be more shallow. This is not always possible, but some quantum computing routines allow for the use of these auxiliary qubits. Let's look at the following example, you want to create a Multi Control X (MCX) gate on 14 control qubits.
First, we will create a simple MCX gate in Qiskit and transpile this to the IBM Cairo machine with 27 qubits. After the optimized transpilation we will print the statistics of the two circuits.
from qiskit import QuantumCircuit, transpile
from qiskit.circuit.library import MCXGate
from qiskit.providers.fake_provider import FakeCairoV2
backend = FakeCairoV2()
mcxgate = MCXGate(14)
qc = QuantumCircuit(15)
qc.mcx([0,1,2,3,4,5,6,7,8,9,10,11,12,13],14)
#optimize as much as possible
qc_basis = transpile(qc, optimization_level=3)
print("Total depth before transpilation: ",qc.depth()) # 1
print("Total depth after transpilation: ",qc_basis.depth()) #32767Well, as you can see, the depth of the initial circuit is only 1, which makes sense because it is just a single MCX gate. Now, when we transpile, the depth explodes to 32767. This is because additional gates are needed to decompose this MCX gate into the native gates that the Cairo device has. Unfortunately, this device does not have a native 14-control MCX gate.
The depth is now so big that executing this circuit on a real quantum device will be impossible.
Now, let's add some auxiliary qubits. We simply change the line of code that adds the MCX gate into the circuit to include auxiliaries, like below. There are various ancilla qubit modes, which gives the best result for me regarding transpiled circuit depth.
qc.mcx([0,1,2,3,4,5,6,7,8,9,10,11,12,13],14,ancilla_qubits=[15,16,17,18,19,20,21,22,23,24,25,26],mode="v-chain")This gives a transpiled depth of only 254, a huge improvement already. The circuit uses 27 qubits, of which 12 are auxiliary qubits. So, there are a lot more qubits but a lot less depth. However, it's probably still too much depth for a current-gen QPU.
Can we improve even further using Classiq? We can get the same MCX gate, designed specifically for the Cairo device, with the QMOD code below. You can synthesise this QMOD code into a logical circuit using the Classiq IDE.
{
"functions": [
{
"name": "main",
"body": [
{
"function": "Mcx",
"function_params": {
"num_ctrl_qubits": 14
}
}
]
}
],
"constraints": {
"optimization_parameter": "depth"
},
"preferences": {
"backend_service_provider": "IBM Quantum",
"backend_name": "Cairo"
}
}This gives a transpiled circuit with a depth of 101, and only uses 21 qubits. This is already an amazing result. Making things even more awesome, the Classiq engine will automatically reuse the released auxiliary qubits later in the circuit if that is useful 🤯.
Let's compare things, with all possible Qiskit MCX options transpiled with optimization_level=3 to the Cairo machine.
| Method | Transpiled qubits | Transpiled depth |
|---|---|---|
| Qiskit no aux | 27 | 95665 |
| Qiskit recursion | 27 | 1599 |
| Qiskit v-chain dirty | 27 | 462 |
| Qiskit v-chain | 27 | 264 |
| Classiq | 21 | 101 |
Even larger MCX
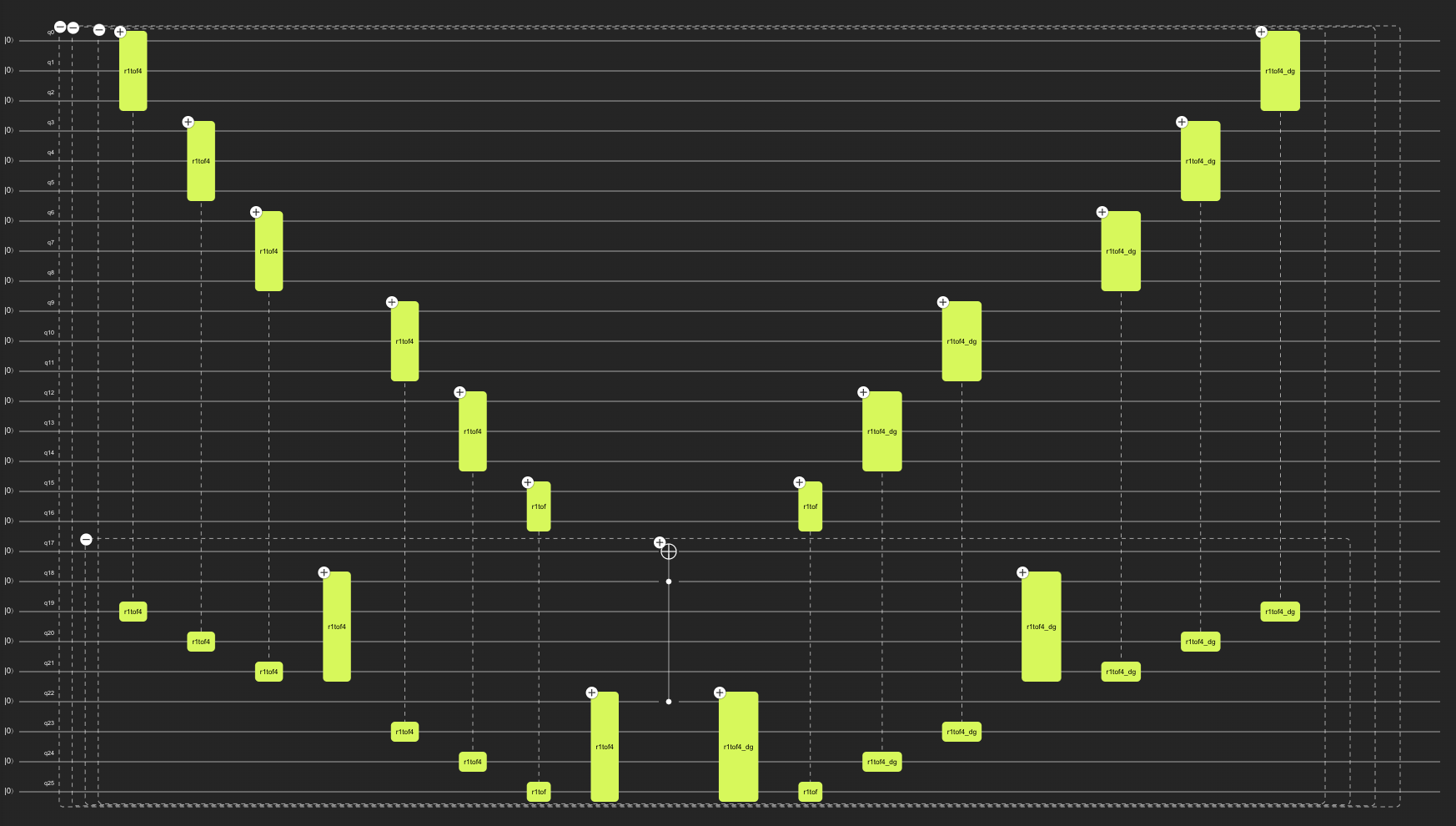
In the Classiq implementation, there are still unused qubits. This raises the question: Could we create a larger, more efficient MCX circuit for the Cairo machine? If we create a 17 control qubit MCX circuit and transpile this to the Cairo machine, we get a depth of 212, and 26 qubits are used, so almost all available qubits of the Cairo machine.
When creating the same MCX in qiskit, we can not use the v-chain ancilla option anymore because there are not enough qubits in the Cairo machine. Therefore recursion mode is used, which gives a transpiled circuit depth of 2347 and uses all 27 qubits.
As you can see, the Classiq Synthesis engine can really optimize the implementation of MCX gates with even fewer ancilla qubits than the best Qiskit implementation.
Stay tuned for a specific post covering hardware-aware synthesis vs transpilation to understand the difference between Qiskit transpilation and the Classiq platform.